Many outcomes of interest have pretty good predictors. It seems that height correlates to performance in basketball (the average height in the NBA is around 6’7″). Faster serves in tennis improve one’s likelihood of winning. IQ scores are known to predict a slew of factors, from income, to chance of being imprisoned, to lifespan.
What’s interesting is what happens to these relationships ‘out on the tail’: extreme outliers of a given predictor are seldom similarly extreme outliers on the outcome it predicts, and vice versa. Although 6’7″ is very tall, it lies within a couple of standard deviations of the median US adult male height – there are many thousands of US men taller than the average NBA player, yet are not in the NBA. Although elite tennis players have very fast serves, if you look at the players serving the fastest serves ever recorded, they aren’t the very best players of their time. It is harder to look at the IQ case due to test ceilings, but again there seems to be some divergence near the top: the very highest earners tend to be very smart, but their intelligence is not in step with their income (their cognitive ability is around +3 to +4 SD above the mean, yet their wealth is much higher than this).[ref]Given income isn’t normally distributed, using SDs might be misleading. But non-parametric ranking to get a similar picture: if Bill Gates is ~+4SD in intelligence, despite being the richest man in america, he is ‘merely’ in the smartest tens of thousands. Looking the other way, one might look at the generally modest achievements of people in high-IQ societies, but there are worries about adverse selection.[/ref]
The trend seems to be that even when two factors are correlated, their tails diverge: the fastest servers are good tennis players, but not the very best (and the very best players serve fast, but not the very fastest); the very richest tend to be smart, but not the very smartest (and vice versa). Why?
Too much of a good thing?
One candidate explanation would be that more isn’t always better, and the correlations one gets looking at the whole population doesn’t capture a reversal at the right tail. Maybe being taller at basketball is good up to a point, but being really tall leads to greater costs in terms of things like agility. Maybe although having a faster serve is better all things being equal, but focusing too heavily on one’s serve counterproductively neglects other areas of one’s game. Maybe a high IQ is good for earning money, but a stratospherically high IQ has an increased risk of productivity-reducing mental illness. Or something along those lines.
I would guess that these sorts of ‘hidden trade-offs’ are common. But, the ‘divergence of tails’ seems pretty ubiquitous (the tallest aren’t the heaviest, the smartest parents don’t have the smartest children, the fastest runners aren’t the best footballers, etc. etc.), and it would be weird if there was always a ‘too much of a good thing’ story to be told for all of these associations. I think there is a more general explanation.
The simple graphical explanation
[Inspired by this essay from Grady Towers]
Suppose you make a scatter plot of two correlated variables. Here’s one I grabbed off google, comparing the speed of a ball out of a baseball pitchers hand compared to its speed crossing crossing the plate:
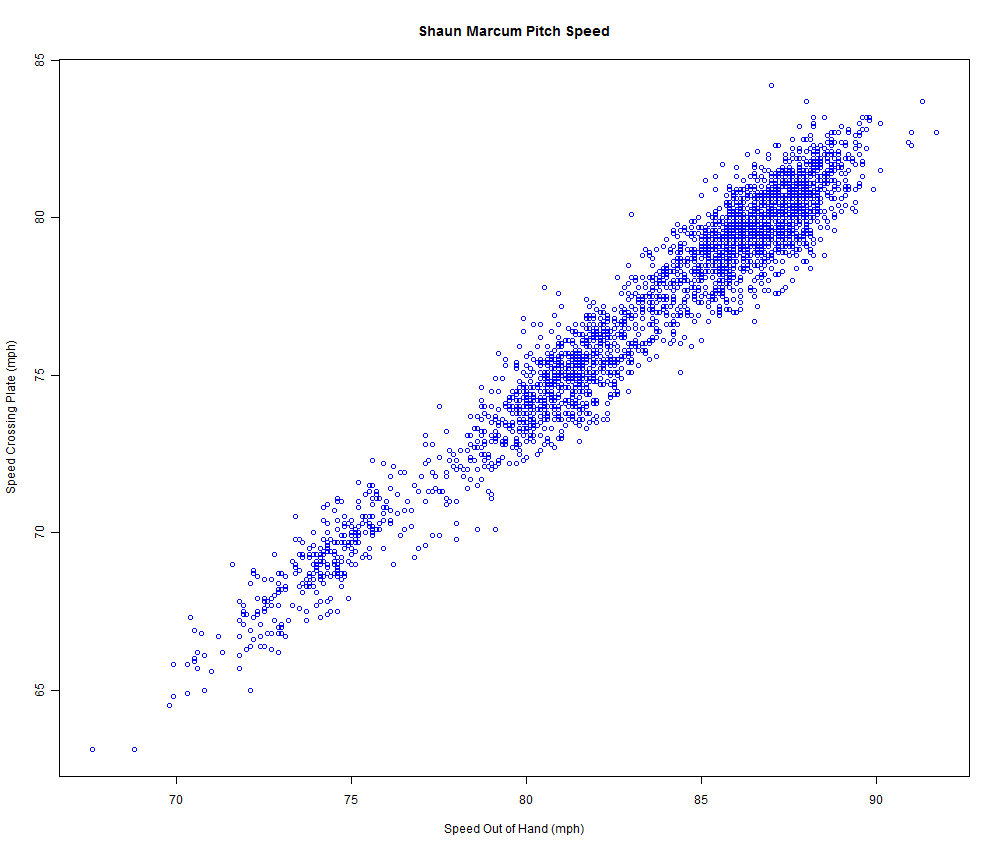
It is unsurprising to see these are correlated (I’d guess the R-square is > 0.8). But if one looks at the extreme end of the graph, the very fastest balls out of the hand aren’t the very fastest balls crossing the plate, and vice versa. This feature is general. Look at this data (again convenience sampled from googling ‘scatter plot’) of this:

Or this:
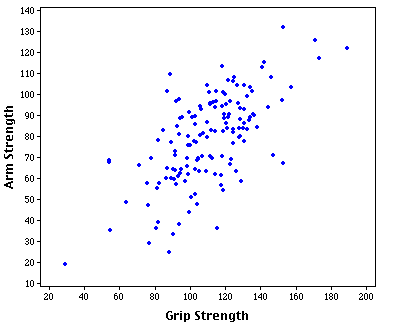
Or this:
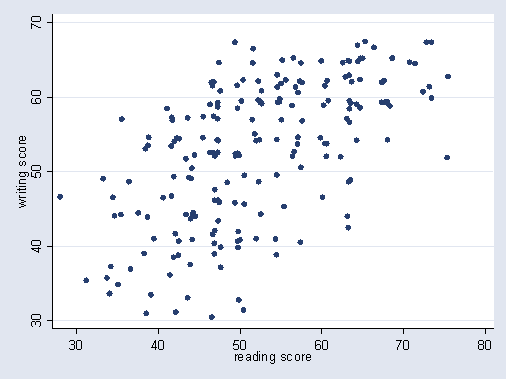
Given a correlation, the envelope of the distribution should form some sort of ellipse, narrower as the correlation goes stronger, and more circular as it gets weaker:[ref]As nshepperd notes below, this depends on something like multivariate CLT. I’m pretty sure this can be weakened: all that is needed, by the lights of my graphical intuition, is that the envelope be concave. It is also worth clarifying the ‘envelope’ is only meant to illustrate the shape of the distribution, rather than some boundary that contains the entire probability density: as suggested by homunq: it is an ‘pdf isobar’ where probability density is higher inside the line than outside it. [/ref]
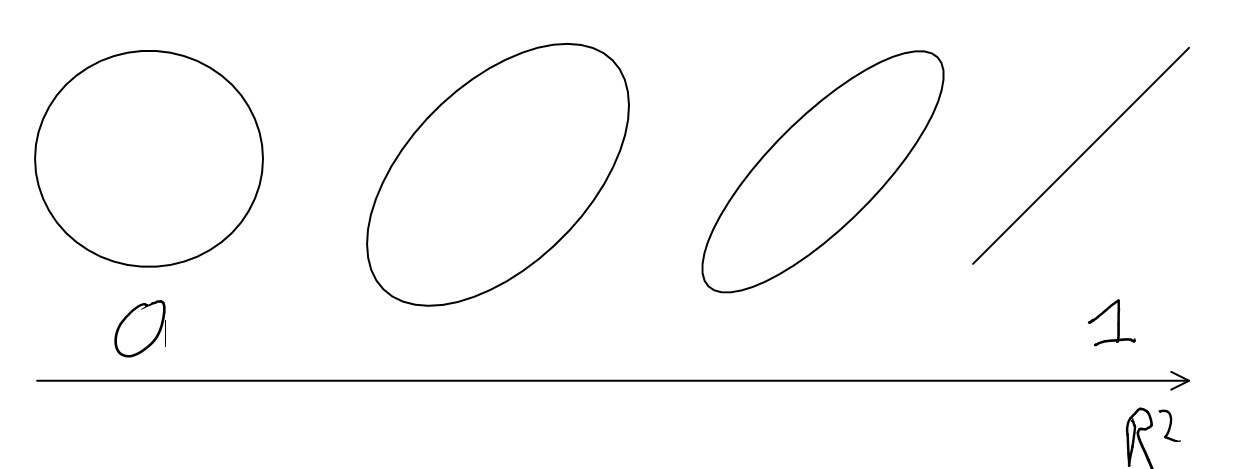
The thing is, as one approaches the far corners of this ellipse, we see ‘divergence of the tails’: as the ellipse doesn’t sharpen to a point, there are bulges where the maximum x and y values lie with sub-maximal y and x values respectively:[ref]
One needs a large enough sample to ‘fill in’ the elliptical population density envelope, and the tighter the correlation, the larger the sample needed to fill in the sub-maximal bulges. The old faithful case is an example where actually you do get a ‘point’, although it is likely an outlier.

[/ref]
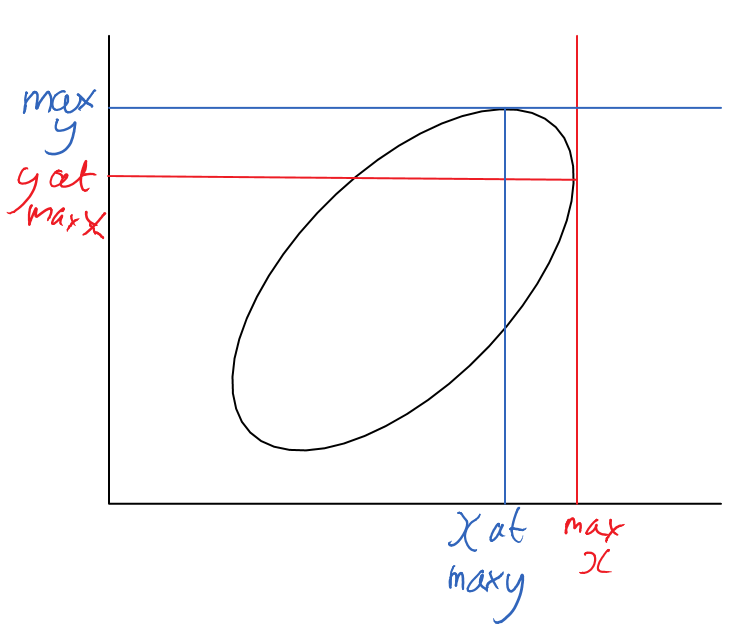
So this offers an explanation why divergence at the tails is ubiquitous. Providing the sample size is largeish, and the correlation not too tight (the tighter the correlation, the larger the sample size required), one will observe the ellipses with the bulging sides of the distribution.
Hence the very best basketball players aren’t the very tallest (and vice versa), the very wealthiest not the very smartest, and so on and so forth for any correlated X and Y. If X and Y are “Estimated effect size” and “Actual effect size”, or “Performance at T”, and “Performance at T+n”, then you have a graphical display of winner’s curse and regression to the mean.
An intuitive explanation of the graphical explanation
It would be nice to have an intuitive handle on why this happens, even if we can be convinced that it happens. Here’s my offer towards an explanation:
The fact that a correlation is less than 1 implies that other things matter to an outcome of interest. Although being tall matters for being good at basketball, strength, agility, hand-eye-coordination matter as well (to name but a few). The same applies to other outcomes where multiple factors play a role: being smart helps in getting rich, but so does being hard working, being lucky, and so on.
For a toy model, pretend that wealth is wholly explained by two factors: intelligence and conscientiousness.[ref]It’s clear that this model is fairly easy to extend to >2 factor cases, but it is worth noting that in cases where the factors are positively correlated, one would need to take whatever component of the factors which are independent of one another.[/ref] Let’s also say these are equally important to the outcome, independent of one another and are normally distributed. So, ceteris paribus, being more intelligent will make one richer, and the toy model stipulates there aren’t ‘hidden trade-offs’: there’s no negative correlation between intelligence and conscientiousness, even at the extremes. Yet the graphical explanation suggests we should still see divergence of the tails: the very smartest shouldn’t be the very richest.
The intuitive explanation would go like this: start at the extreme tail – +4SD above the mean for intelligence, say. Although this gives them a massive boost to their wealth, we’d expect them to be average with respect to conscientiousness (we’ve stipulated they’re independent). Further, as this ultra-smart population is small, we’d expect them to fall close to the average in this other independent factor: with 10 people at +4SD, you wouldn’t expect any of them to be +2SD in conscientiousness.
Move down the tail to less extremely smart people – +3SD say. These people don’t get such a boost to their wealth from their intelligence, but there should be a lot more of them (if 10 at +4SD, around 500 at +3SD), this means one should expect more variation in conscientiousness – it is much less surprising to find someone +3SD in intelligence and also +2SD in conscientiousness, and in the world where these things were equally important, they would ‘beat’ someone +4SD in intelligence but average in conscientiousness. Although a +4SD intelligence person will likely be better than a given +3SD intelligence person (the mean conscientiousness in both populations is 0SD, and so the average wealth of the +4SD intelligence population is 1SD higher than the 3SD intelligence people), the wealthiest of the +4SDs will not be as good as the best of the much larger number of +3SDs. The same sort of story emerges when we look at larger numbers of factors, and in cases where the factors contribute unequally to the outcome of interest.
When looking at a factor known to be predictive of an outcome, the largest outcome values will occur with sub-maximal factor values, as the larger population increases the chances of ‘getting lucky’ with the other factors:
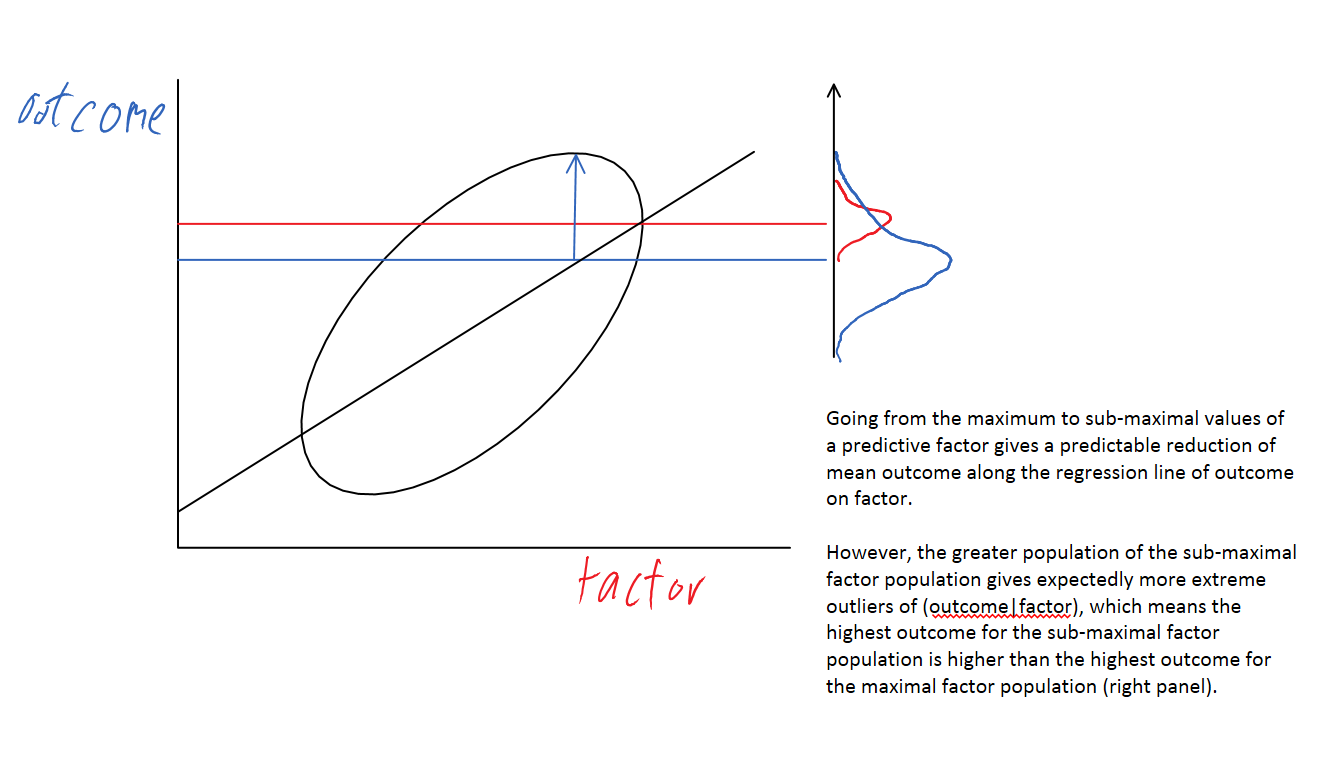
So that’s why the tails diverge.
A parallel geometric explanation
There’s also a geometric explanation. The R-square measure of correlation between two sets of data is the same as the cosine of the angle between them when presented as vectors in N-dimensional space (explanations, derivations, and elaborations here, here, and here).[ref]My intuition is that in cartesian coordinates the R-square between correlated X and Y is actually also the cosine of the angle between the regression lines of X on Y and Y on X. But I can’t see an obvious derivation, and I’m too lazy to demonstrate it myself. Sorry![/ref] So here’s another intuitive handle for tail divergence:

Grant a factor correlated with an outcome, which we represent with two vectors at an angle theta, the inverse cosine equal the R-squared. ‘Reading off the expected outcome given a factor score is just moving along the factor vector and multiplying by cosine theta to get the distance along the outcome vector. As cos theta is never greater than 1, we see regression to the mean. The geometrical analogue to the tails coming apart is the absolute difference in length along factor versus length along outcome|factor scales with the length along the factor; the gap between extreme values of a factor and the less extreme values of the outcome grows linearly as the factor value gets more extreme. For concreteness (and granting normality), an R-square of 0.5 (corresponding to an angle of sixty degrees) means that +4SD (~1/15000) on a factor will be expected to be ‘merely’ +2SD (~1/40) in the outcome – and an R-square of 0.5 is remarkably strong in the social sciences, implying it accounts for half the variance.[ref]Another intuitive dividend is that this makes it clear why you can by R-squared to move between z-scores of correlated normal variables, which wasn’t straightforwardly obvious to me.[/ref] The reverse – extreme outliers on outcome are not expected to be so extreme an outlier on a given contributing factor – follows by symmetry.
Endnote: EA relevance
I think this is interesting in and of itself, but it has relevance to Effective Altruism, given it generally focuses on the right tail of various things (What are the most effective charities? What is the best career? etc.) It generally vindicates worries about regression to the mean or winner’s curse, and suggests that these will be pretty insoluble in all cases where the populations are large: even if you have really good means of assessing the best charities or the best careers so that your assessments correlate really strongly with what ones actually are the best, the very best ones you identify are unlikely to be actually the very best, as the tails will diverge.
This probably has limited practical relevance. Although you might expect that one of the ‘not estimated as the very best’ charities is in fact better than your estimated-to-be-best charity, you don’t know which one, and your best bet remains your estimate (in the same way – at least in the toy model above – you should bet a 6’11” person is better at basketball than someone who is 6’4″.)
There may be spread betting or portfolio scenarios where this factor comes into play – perhaps instead of funding AMF to diminishing returns when its marginal effectiveness dips below charity #2, we should be willing to spread funds sooner.[ref]I’d intuit, but again I can’t demonstrate, the case for this becomes stronger with highly skewed interventions where almost all the impact is focused in relatively low probability channels, like averting a very specified existential risk.[/ref] Mainly, though, it should lead us to be less self-confident.
[Cross: LessWrong]
